Architecture Overview
Kahuna is designed to be scalable, consistent, and easy to use. Developers might wonder how this is achieved which is why this section aims to explain the key concepts behind Kahuna’s architecture.
Kahuna's architecture operates as a highly scalable, fault-tolerant distributed system that combines lock management, key-value storage, and sequencing capabilities. At its foundation lies a distributed key-value storage model where data is organized into discrete partitions similar to sharding mechanisms in other distributed systems. These partitions function as independent units that can be distributed and managed across the entire node cluster.
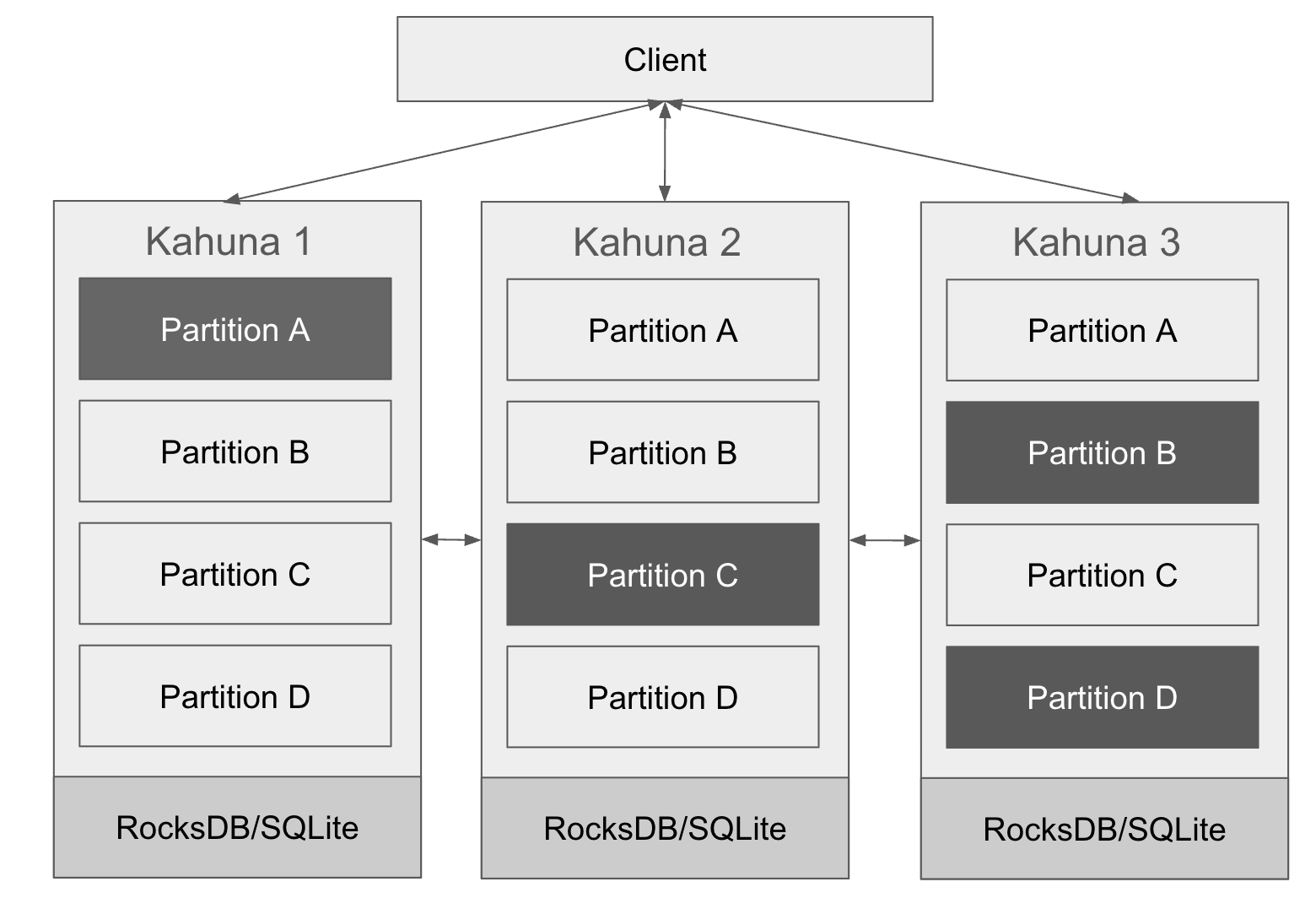
In the previous diagram, we can see a cluster of three nodes named Kahuna 1, 2, and 3. Each of these nodes shows the initial partitions available—labeled partition A, B, C, and D. The leader of each partition is highlighted in dark gray. A leader is responsible for processing reads and writes consistently for its assigned partition.
With this small example, we can already observe some of the key characteristics of Kahuna's architecture:
-
It’s possible to have multiple nodes (Kahuna 1, 2, and 3) in a cluster, each replicating the full database state. Replication is synchronous via Raft, ensuring that any node can become the leader of a partition if another node fails or becomes unavailable.
-
The leader nodes for specific partitions are responsible for serving reads and writes in a serialized manner, offering strong consistency. This guarantees that the value read by a client is the most recent and committed version.
-
With multiple partitions and distributed leadership across the cluster nodes, Kahuna promotes optimal use of computing resources. In other words, all nodes act as both primaries and secondaries at the same time.
-
A client can contact any node for a read or write operation. Internally, Kahuna nodes locate the leader of the appropriate partition transparently, so the client doesn’t need to know where the leader is.
-
For on-disk storage, Kahuna leverages battle-tested embedded databases like RocksDB and SQLite, each with their own strengths. Kahuna then acts as a distributed replication and high-level coordination layer built on top of these solid embedded storage engines.
Additionally, to make the system more scalable and optimize compute resource usage:
- New nodes can be added to the cluster on the fly. These new nodes can eventually become leaders of partitions once they are caught up with the latest activity.
- Nodes can be removed from the cluster for maintenance or decommissioning. Leadership distribution is automatically rebalanced while maintaining consistency.
- A general monitoring algorithm tracks partition activity to determine if a partition is too large (based on a configured threshold) or experiencing too much activity (becoming a hotspot). When this happens, the partition is split into two, distributing its size and load across two available nodes in the cluster.
Goals of Kahuna
Building distributed systems is hard, and many problems can involve edge cases that are extremely difficult to solve. Solutions are not always perfect for every scenario. Kahuna is designed to abstract much of this complexity by offering a simple and intuitive API, making it easier for developers to build and manage distributed applications.
Kahuna is designed to address the following challenges:
- Offer a predictable and easy-to-use API for distributed locks, including leases and fencing tokens, along with practical guidance for implementing mutual exclusion in distributed systems.
- Provide a robust key/value system that prioritizes usability, data durability and consistency. Additionally, it should offer a simple yet powerful interface for multi-key distributed transactions, while recognizing that some scenarios don’t require durability and instead benefit from a high-performance ephemeral mode.
- Propose a pragmatic distributed sequencing system that gives developers a ready-made solution for generating unique, ordered values in a distributed environment.
- Ensure strong data consistency, even in multi-node, multi-partition clusters. Kahuna abstracts away the complexity of distributed key/value transactions and shields developers from issues like stale reads or inconsistent state.
- Enable high availability, allowing any node in the cluster to accept reads and writes. It also distributes load intelligently and minimizes downtime due to cluster topology changes.
- Developed in the C# programming language and the modern .NET platform, Kahuna empowers developers to hack, extend, and customize the database to fit their specific needs —whether through configuration or plugin-based extensions. Additionally, it’s built to run in a robust, multi-threaded environment that leverages all available CPU cores and computing power.
- Reduce vendor lock-in by being deployable in any environment or cloud provider.
Raft-Based Consensus
Consensus across the distributed system is achieved through the Raft protocol, with each partition in Kahuna being governed by its own Raft group. This protocol ensures consistent replication of all changes across multiple nodes, thereby establishing the foundation for Kahuna's fault tolerance and high availability characteristics.
Within each Raft group, the consensus mechanism designates one node as the leader through an election process. This leader node coordinates all write operations for its assigned partition. To maintain consistency, all operations are recorded as log entries which are systematically replicated to follower nodes. This replication process ensures that data remains consistent across all nodes responsible for a particular partition.
Scalability and Fault Tolerance
Horizontal scalability is achieved through dynamic partition management. Partitions can be automatically split and redistributed across nodes to achieve optimal load balancing. This architecture supports linear scalability as additional nodes are integrated into the cluster, allowing Kahuna to expand its capacity proportionally with infrastructure growth.
High availability is ensured through Raft-based replication mechanisms. The system maintains operation even when individual nodes fail, as data remains accessible through replicas. Kahuna's recovery processes are designed to restore system integrity after failures without compromising committed transactions, maintaining both data consistency and service availability.
Performance Optimizations
While Kahuna maintains strong consistency guarantees through the Raft protocol, it also incorporates various performance optimizations. Asynchronous replication techniques are employed where appropriate to enhance data replication efficiency and minimize read operation latency without sacrificing consistency requirements.
Background maintenance processes continuously perform compaction and garbage collection operations to reclaim storage space and memory resources. These automated maintenance routines help preserve system performance by systematically removing obsolete data versions that are no longer needed for transaction isolation or recovery purposes.
When to use Kahuna?
Kahuna is a distributed key/value database that offers both persistent and ephemeral durability, adapting to many different use cases. It also provides ready-to-use abstractions for locks and sequences. It has many useful applications across different areas, which may also overlap with functionality provided by other existing databases.
Its versatility ranges from strong persistence—with data synchronously replicated across multiple nodes to ensure no data is lost in the event of failures—to the speed of in-memory storage, adapting to workloads that require low latency.
In both cases, strong consistency is guaranteed. Additionally, transactions that manipulate key/value pairs of any durability are fully supported, opening up a world of possibilities for building reliable and scalable systems.
Written in modern C# and running on the latest high-performance versions of .NET 8 and 9, Kahuna offers developers the ability to extend, adapt, and enhance it to meet their own needs easily and efficiently.